# read bytes from our valid JPEG and return them in a mutable bytearray defget_bytes(filename):
f = open(filename, "rb").read()
returnbytearray(f)
defbit_flip(data):
num_of_flips = int((len(data) - 4) * 0.01)
indexes = range(4, (len(data) - 4))
chosen_indexes = []
# iterate selecting indexes until we've hit our num_of_flips number counter = 0 while counter < num_of_flips: chosen_indexes.append(random.choice(indexes)) counter += 1
for x in chosen_indexes: current = data[x] current = (bin(current).replace("0b","")) current = "0" * (8 - len(current)) + current indexes = range(0,8)
picked_index = random.choice(indexes)
new_number = []
# our new_number list now has all the digits, example: ['1', '0', '1', '0', '1', '0', '1', '0'] for i in current: new_number.append(i)
# if the number at our randomly selected index is a 1, make it a 0, and vice versa if new_number[picked_index] == "1": new_number[picked_index] = "0" else: new_number[picked_index] = "1"
# create our new binary string of our bit-flipped number current = '' for i in new_number: current += i
# convert that string to an integer current = int(current,2)
# change the number in our byte array to our new number we just constructed data[x] = current
return data
# create new jpg with mutated data defcreate_new(data):
f = open("mutated.jpg", "wb+") f.write(data) f.close()
magic num 就是指有些数字是特殊的,我们可以选择直接插入magic num 来更有效的进行变异
1 2 3 4 5 6 7 8 9 10
0xFF 0x7F 0x00 0xFFFF 0x0000 0xFFFFFFFF 0x00000000 0x80000000 <-- minimum 32-bit int 0x40000000 <-- just half of that amount Ox7FFFFFFF <-- max 32-bit int
一些文件格式标志等
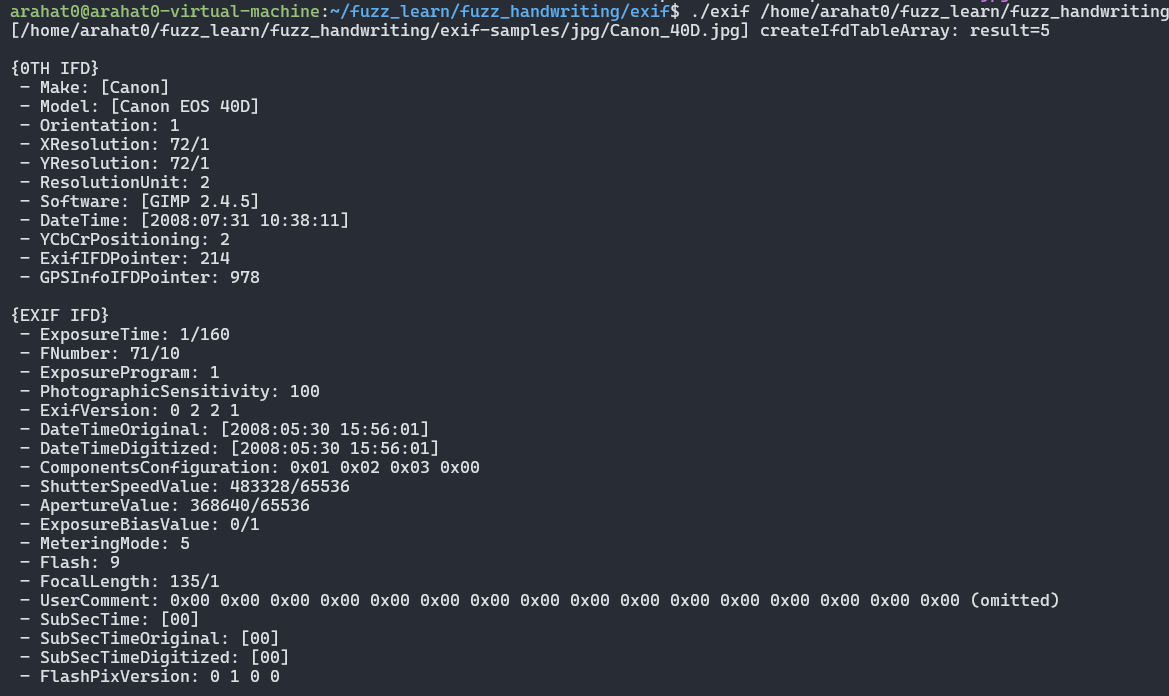
JPEG 文件: 开头的字节为 FF D8
GIF 文件: 开头的字节为 47 49 46 38
ELF可执行文件:开头的字节为 7F 45 4C 46
我们这里有一个对magic num 的初步选择
1字节修改 如果选择的魔数是(1,255),则 data 在选定的索引位置的值被设置为255 如果是(1,127),则设置为127 如果是(1,0),则设置为0
2字节修改 如果选择的魔数是 (2,255),则 data 在选定的索引位置及其后的位置的值被设置为255 如果是(2,0),则这两个位置都被设置为0
# read bytes from our valid JPEG and return them in a mutable bytearray defget_bytes(filename): f = open(filename, "rb").read() returnbytearray(f)
defbit_flip(data):
num_of_flips = int((len(data) - 4) * 0.01) indexes = range(4, (len(data) - 4)) chosen_indexes = [] # iterate selecting indexes until we've hit our num_of_flips number counter = 0 while counter < num_of_flips: chosen_indexes.append(random.choice(indexes)) counter += 1
for x in chosen_indexes: current = data[x] current = (bin(current).replace("0b","")) current = "0" * (8 - len(current)) + current indexes = range(0,8)
picked_index = random.choice(indexes)
new_number = []
# our new_number list now has all the digits, example: ['1', '0', '1', '0', '1', '0', '1', '0'] for i in current: new_number.append(i)
# if the number at our randomly selected index is a 1, make it a 0, and vice versa if new_number[picked_index] == "1": new_number[picked_index] = "0" else: new_number[picked_index] = "1"
# create our new binary string of our bit-flipped number current = '' for i in new_number: current += i
# convert that string to an integer current = int(current,2)
# change the number in our byte array to our new number we just constructed data[x] = current
# here we are hardcoding all the byte overwrites for all of the tuples that begin (1, ) if picked_magic[0] == 1: if picked_magic[1] == 255: # 0xFF data[picked_index] = 255 elif picked_magic[1] == 127: # 0x7F data[picked_index] = 127 elif picked_magic[1] == 0: # 0x00 data[picked_index] = 0
# here we are hardcoding all the byte overwrites for all of the tuples that begin (2, ) elif picked_magic[0] == 2: if picked_magic[1] == 255: # 0xFFFF data[picked_index] = 255 data[picked_index + 1] = 255 elif picked_magic[1] == 0: # 0x0000 data[picked_index] = 0 data[picked_index + 1] = 0
# here we are hardcoding all of the byte overwrites for all of the tuples that being (4, ) elif picked_magic[0] == 4: if picked_magic[1] == 255: # 0xFFFFFFFF data[picked_index] = 255 data[picked_index + 1] = 255 data[picked_index + 2] = 255 data[picked_index + 3] = 255 elif picked_magic[1] == 0: # 0x00000000 data[picked_index] = 0 data[picked_index + 1] = 0 data[picked_index + 2] = 0 data[picked_index + 3] = 0 elif picked_magic[1] == 128: # 0x80000000 data[picked_index] = 128 data[picked_index + 1] = 0 data[picked_index + 2] = 0 data[picked_index + 3] = 0 elif picked_magic[1] == 64: # 0x40000000 data[picked_index] = 64 data[picked_index + 1] = 0 data[picked_index + 2] = 0 data[picked_index + 3] = 0 elif picked_magic[1] == 127: # 0x7FFFFFFF data[picked_index] = 127 data[picked_index + 1] = 255 data[picked_index + 2] = 255 data[picked_index + 3] = 255 return data # create new jpg with mutated data defcreate_new(data):
f = open("mutated.jpg", "wb+") f.write(data) f.close()
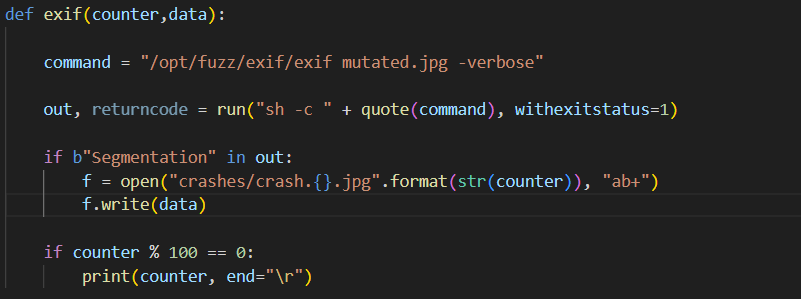
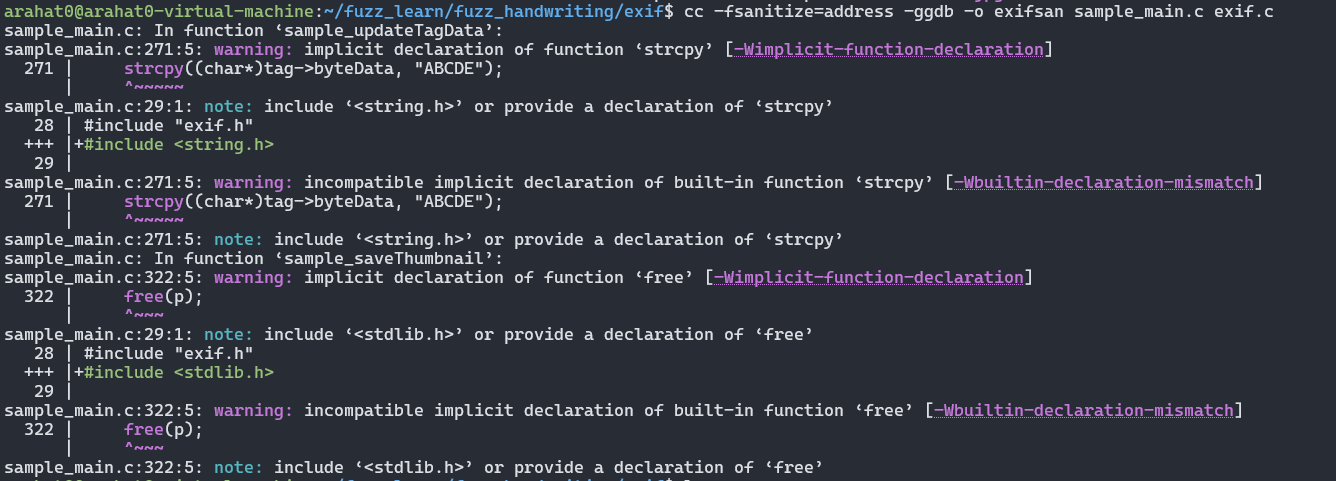
import sys import random from pexpect import run from pipes import quote
# read bytes from our valid JPEG and return them in a mutable bytearray defget_bytes(filename): f = open(filename, "rb").read() returnbytearray(f)
defbit_flip(data):
num_of_flips = int((len(data) - 4) * 0.01) indexes = range(4, (len(data) - 4)) chosen_indexes = [] # iterate selecting indexes until we've hit our num_of_flips number counter = 0 while counter < num_of_flips: chosen_indexes.append(random.choice(indexes)) counter += 1
for x in chosen_indexes: current = data[x] current = (bin(current).replace("0b","")) current = "0" * (8 - len(current)) + current indexes = range(0,8)
picked_index = random.choice(indexes)
new_number = []
# our new_number list now has all the digits, example: ['1', '0', '1', '0', '1', '0', '1', '0'] for i in current: new_number.append(i)
# if the number at our randomly selected index is a 1, make it a 0, and vice versa if new_number[picked_index] == "1": new_number[picked_index] = "0" else: new_number[picked_index] = "1"
# create our new binary string of our bit-flipped number current = '' for i in new_number: current += i
# convert that string to an integer current = int(current,2)
# change the number in our byte array to our new number we just constructed data[x] = current
# here we are hardcoding all the byte overwrites for all of the tuples that begin (1, ) if picked_magic[0] == 1: if picked_magic[1] == 255: # 0xFF data[picked_index] = 255 elif picked_magic[1] == 127: # 0x7F data[picked_index] = 127 elif picked_magic[1] == 0: # 0x00 data[picked_index] = 0
# here we are hardcoding all the byte overwrites for all of the tuples that begin (2, ) elif picked_magic[0] == 2: if picked_magic[1] == 255: # 0xFFFF data[picked_index] = 255 data[picked_index + 1] = 255 elif picked_magic[1] == 0: # 0x0000 data[picked_index] = 0 data[picked_index + 1] = 0
# here we are hardcoding all of the byte overwrites for all of the tuples that being (4, ) elif picked_magic[0] == 4: if picked_magic[1] == 255: # 0xFFFFFFFF data[picked_index] = 255 data[picked_index + 1] = 255 data[picked_index + 2] = 255 data[picked_index + 3] = 255 elif picked_magic[1] == 0: # 0x00000000 data[picked_index] = 0 data[picked_index + 1] = 0 data[picked_index + 2] = 0 data[picked_index + 3] = 0 elif picked_magic[1] == 128: # 0x80000000 data[picked_index] = 128 data[picked_index + 1] = 0 data[picked_index + 2] = 0 data[picked_index + 3] = 0 elif picked_magic[1] == 64: # 0x40000000 data[picked_index] = 64 data[picked_index + 1] = 0 data[picked_index + 2] = 0 data[picked_index + 3] = 0 elif picked_magic[1] == 127: # 0x7FFFFFFF data[picked_index] = 127 data[picked_index + 1] = 255 data[picked_index + 2] = 255 data[picked_index + 3] = 255 return data # create new jpg with mutated data defcreate_new(data):
f = open("mutated.jpg", "wb+") f.write(data) f.close()
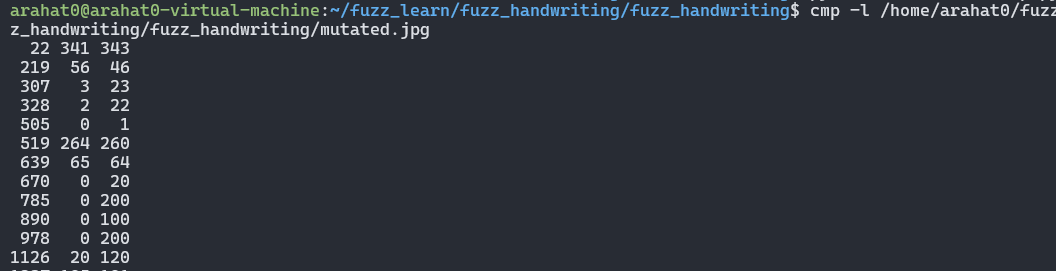
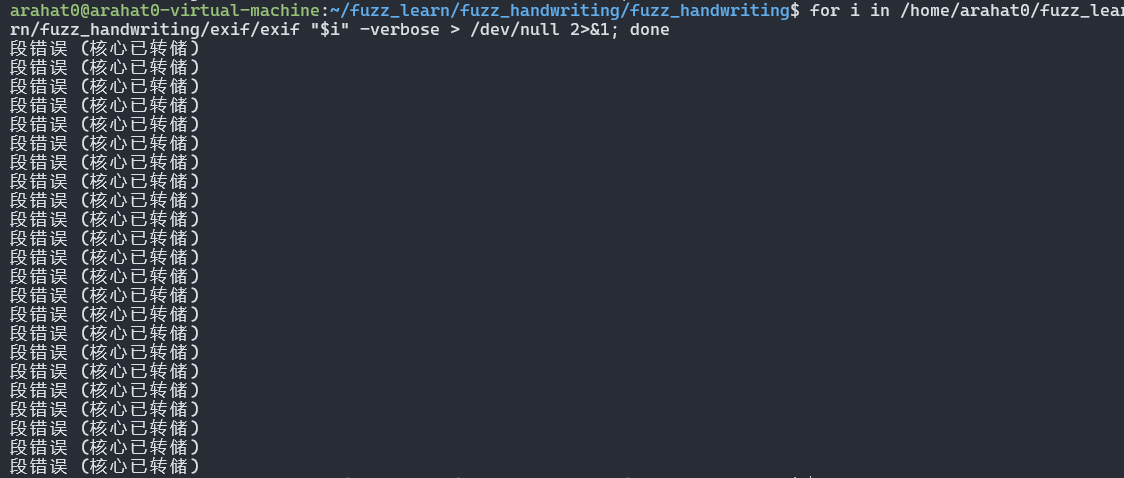
for i in /home/arahat0/fuzz_learn/fuzz_handwriting/fuzz_handwriting/crashes/*.jpg; do /home/arahat0/fuzz_learn/fuzz_handwriting/exif/exif "$i" -verbose > /dev/null 2>&1; done